The Best Traffic Bot and Website Automation Software
TrafficBotPro empowers you to effortlessly automate any web task and send mass traffic to websites with
ease



Earn money by clicking ads
on your website or beat
your competitors by
clicking their AD
automatically.
Join popular freelancing
platforms like Fiverr, Seo
Clerks and start selling
website traffic there and
make some money!
For batch processing images at high DPI:
Get-ChildItem -Filter "*.pdf" | ForEach-Object $output = "$($_.BaseName).txt" pdftotext $_.FullName $output Write-Host "Processed $($_.Name)"
Use -nopgbrk to avoid page break markers, and -enc UTF-8 for Unicode output. Convert to Images (pdftoppm) pdftoppm -png report.pdf page Creates page-1.png , page-2.png , etc. For JPEG, replace -png with -jpeg . Adjust DPI with -rx 300 -ry 300 . Extract All Images (pdfimages) pdfimages -j report.pdf images This dumps every raw image as images-000.jpg , images-001.ppm , etc. The -j flag saves JPEGs as JPEGs; otherwise, they become PPM/PBM.
For image extraction: pdfimages took 0.9 seconds vs. Acrobat’s 7 seconds. The performance delta is dramatic, especially on older hardware or in batch scenarios. Here’s a PowerShell one-liner to extract text from all PDFs in a folder:
| Tool | Time to extract all text | Memory usage | |------|------------------------|--------------| | xpdf pdftotext | 0.47 seconds | 8 MB | | Python PyPDF2 | 1.8 seconds | 45 MB | | Adobe Acrobat (Save As Text) | 6.2 seconds | 210 MB | | Microsoft Edge “Save as Text” | 2.1 seconds | 190 MB |
Look for → “Windows” → “64-bit” (or 32-bit if needed). The filename is typically xpdf-tools-win-4.04.zip . One Last Tip Don’t confuse xpdf-tools with the older Xpdf viewer (which had a GUI). The tools are a separate download. And if you’re on Linux, you can install via apt install xpdf-utils or similar – but on Windows, this ZIP is your best bet.
The 4.04 release is stable, well-tested, and free (under the GPLv2). It doesn’t phone home, doesn’t display ads, and doesn’t mysteriously expire. It just works – even on Windows 11, Windows Server 2022, and Windows 10 LTSC.
TrafficBotPro is a software web automation software that allows you to hide and control your digital
fingerprint by spoofing all parameters that websites can see. By masking these settings, you can bypass
anti-fraud systems by impersonating your real internet identity.
It helps you create a large number of profiles, each with its own digital fingerprint. These profiles do not
overlap with each other, so the website cannot ban your account. This is useful for performing various tasks
on the Internet.
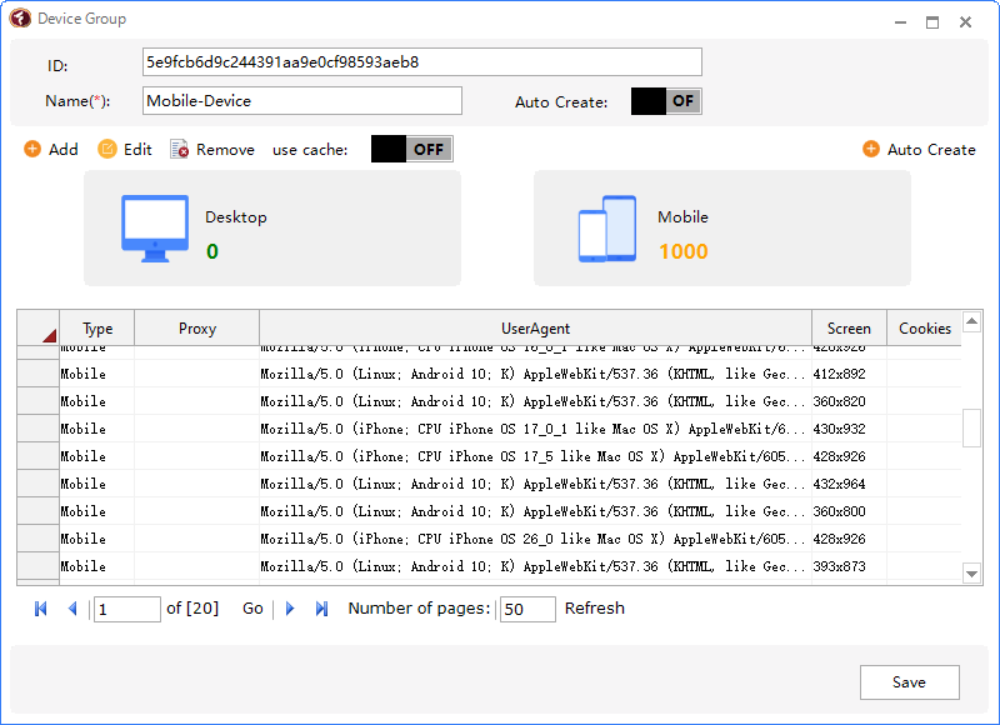
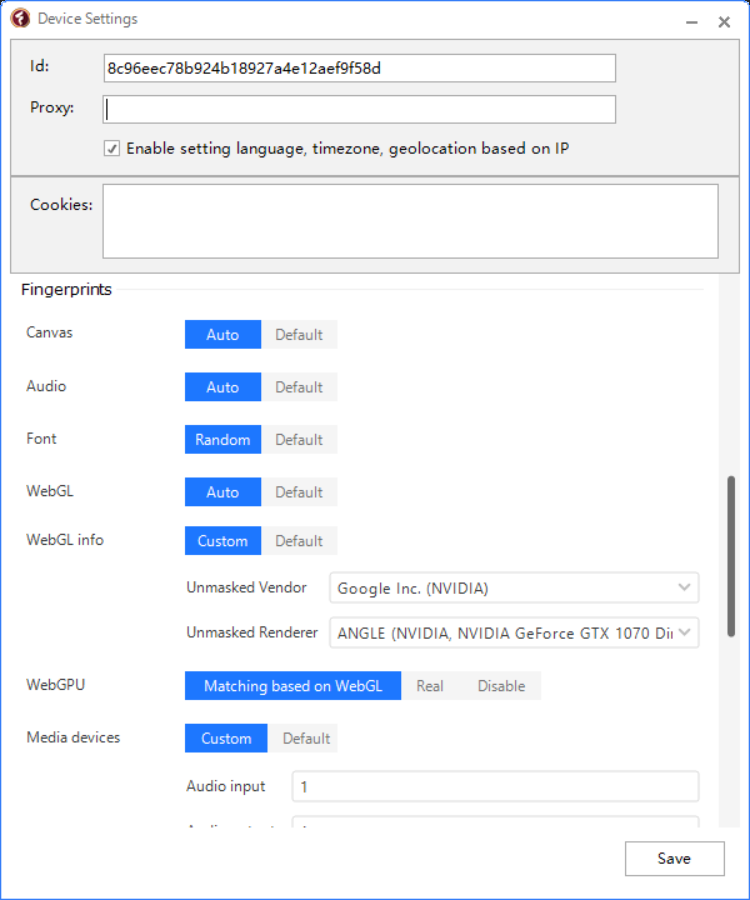
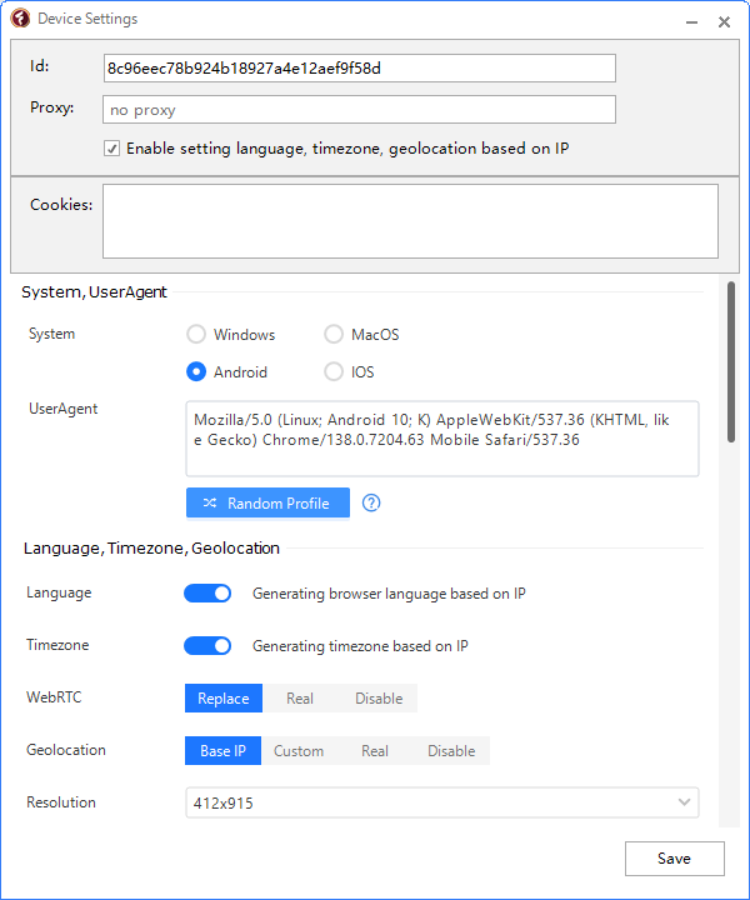
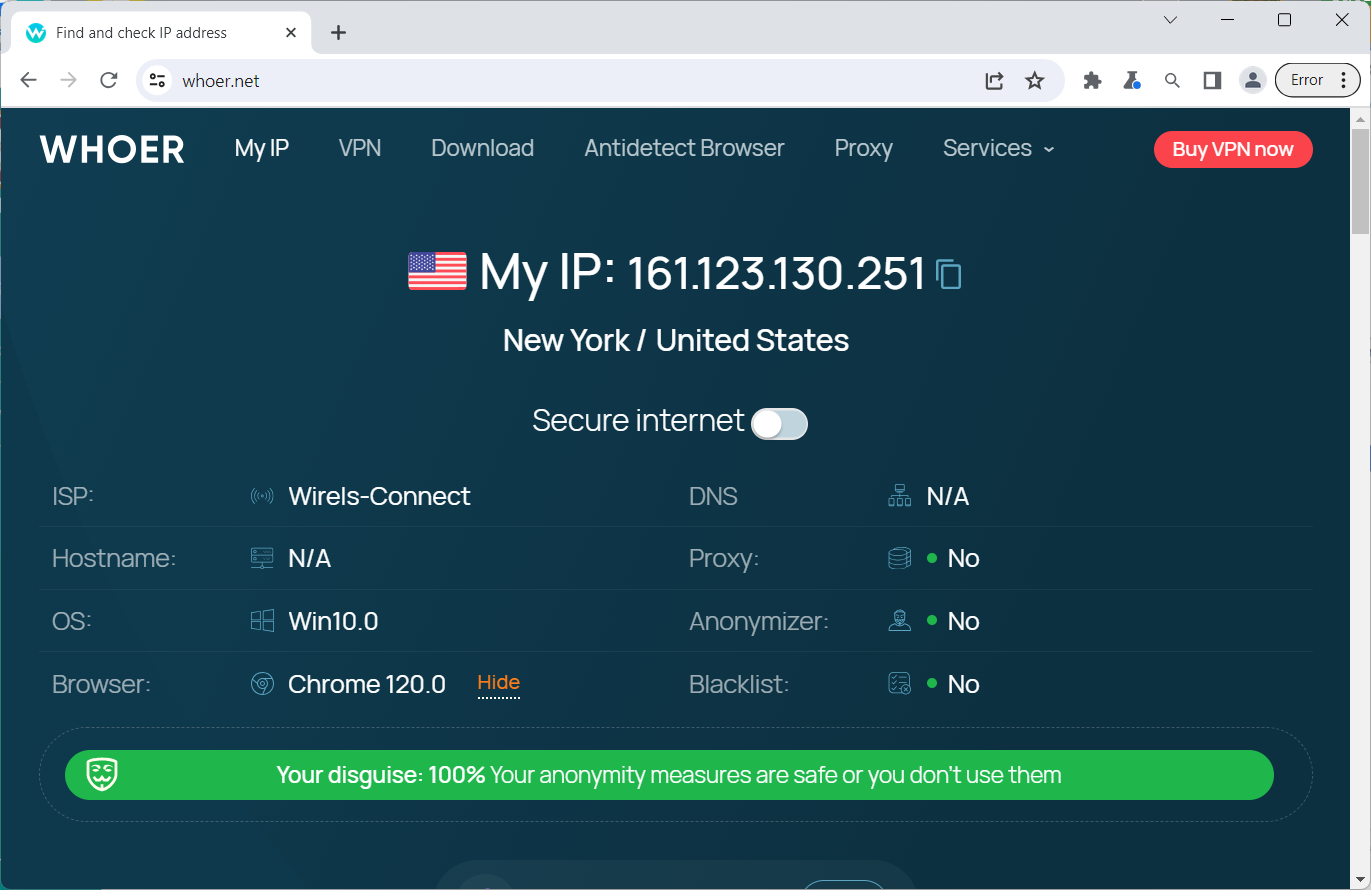
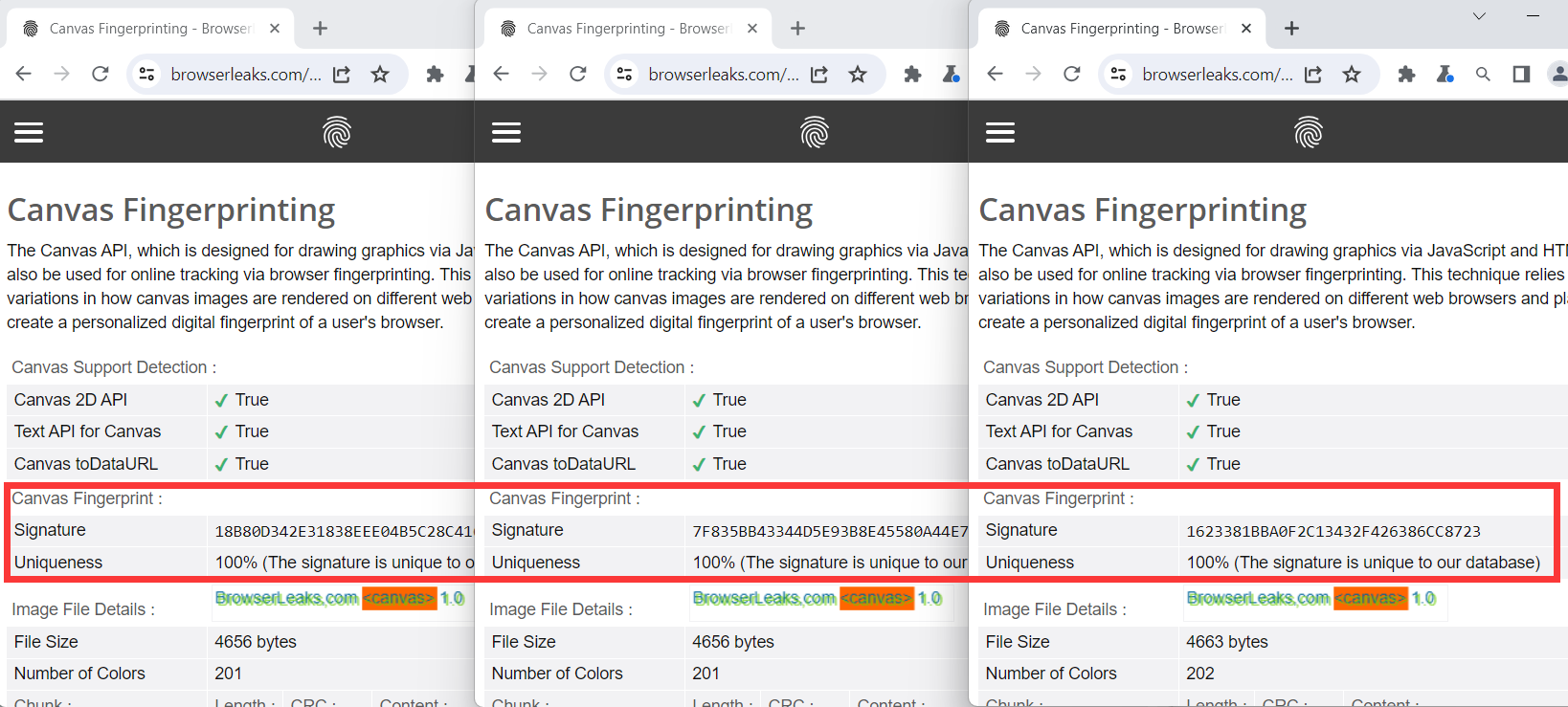
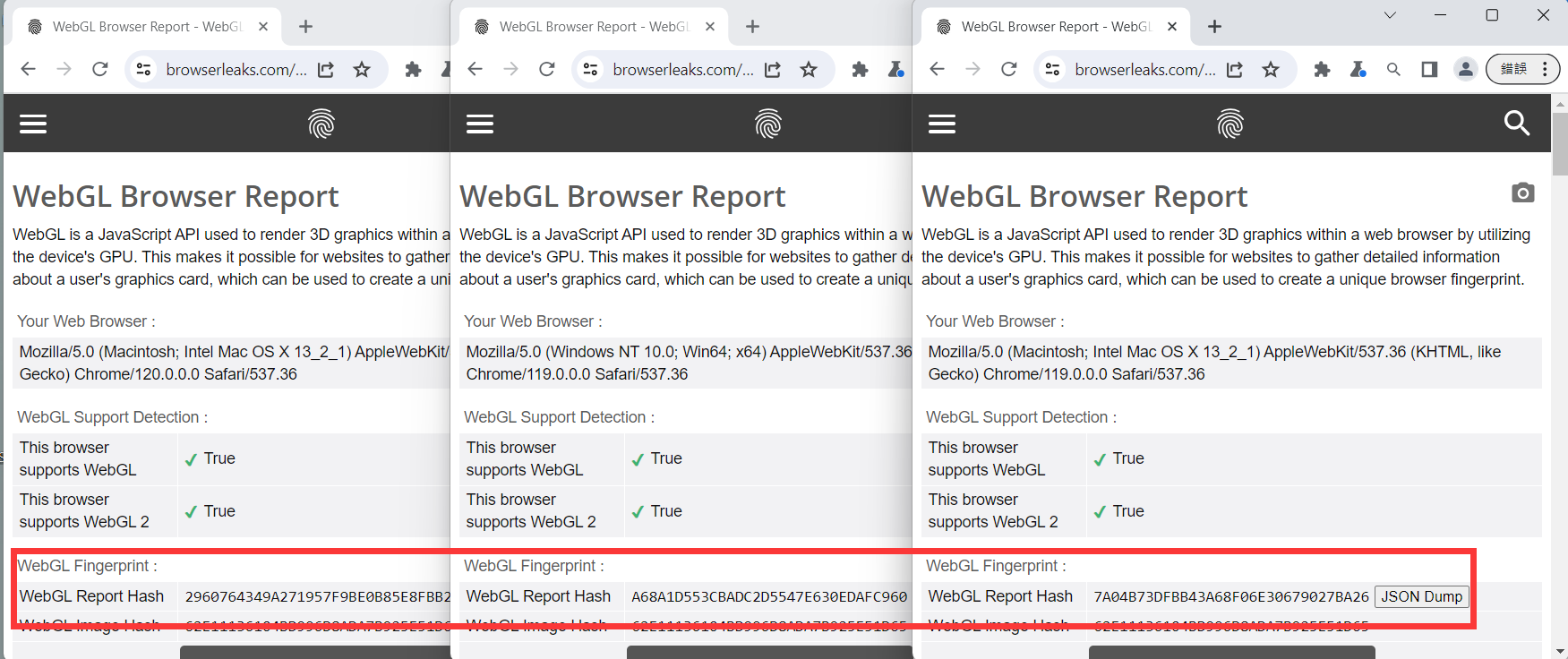
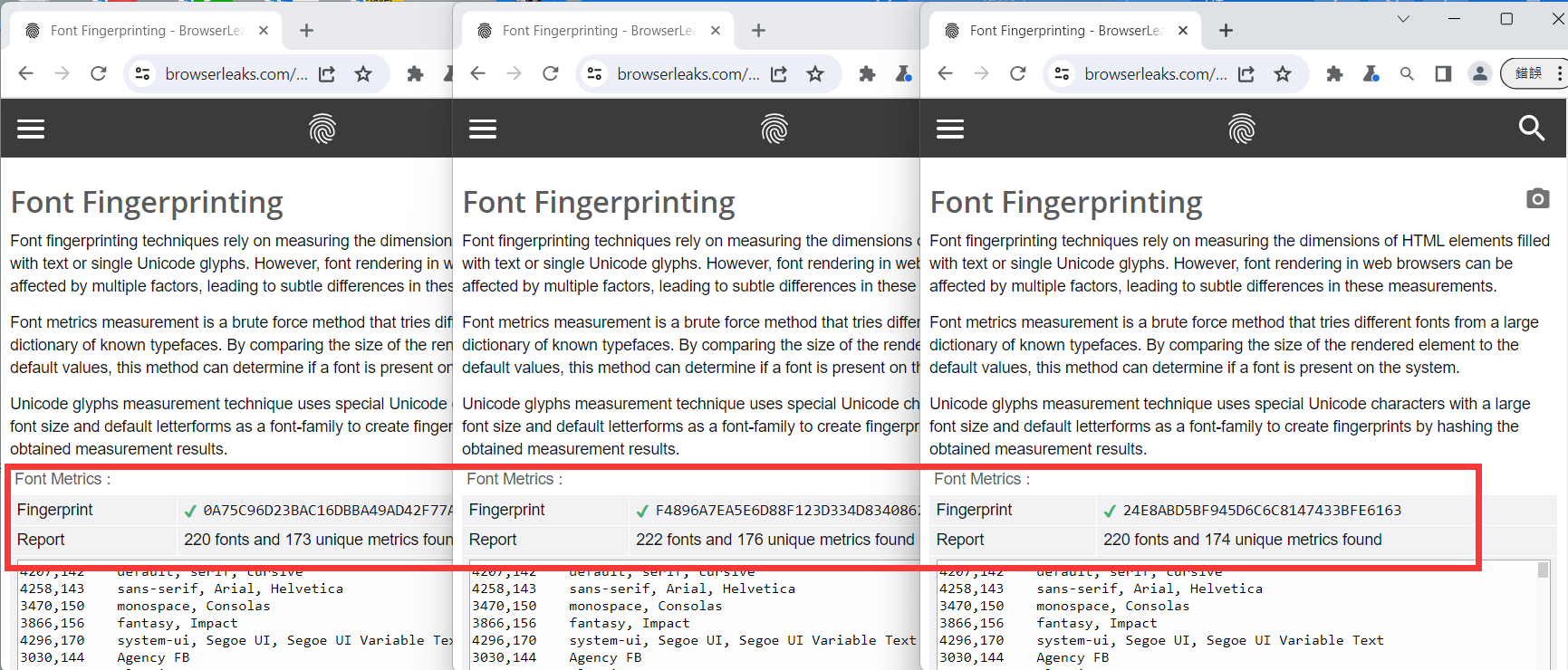
Our software approaches browser fingerprinting in a completely indigenous way. Instead of trying to prevent websites from reading your computer’s fingerprint, our software allows reading it but replaces your original fingerprint with a different one. When you use a proxy IP, our software is fully different to other software that only add a proxy to your browser to work, our software will set the timezone, language, DNS and location etc... is matched to your proxy IP, that will make you looks like a real people from the proxy IP. Our software can also generate different device fingerprint and bind different fingerprint with your accounts. Once the account is bind with proxy IP, device fingerprint and other settings, the account will use these settings all the time with all operation. That is why you can use our software to mange and operate many accounts with different proxy safely.


For batch processing images at high DPI:
Get-ChildItem -Filter "*.pdf" | ForEach-Object $output = "$($_.BaseName).txt" pdftotext $_.FullName $output Write-Host "Processed $($_.Name)"
Use -nopgbrk to avoid page break markers, and -enc UTF-8 for Unicode output. Convert to Images (pdftoppm) pdftoppm -png report.pdf page Creates page-1.png , page-2.png , etc. For JPEG, replace -png with -jpeg . Adjust DPI with -rx 300 -ry 300 . Extract All Images (pdfimages) pdfimages -j report.pdf images This dumps every raw image as images-000.jpg , images-001.ppm , etc. The -j flag saves JPEGs as JPEGs; otherwise, they become PPM/PBM.
For image extraction: pdfimages took 0.9 seconds vs. Acrobat’s 7 seconds. The performance delta is dramatic, especially on older hardware or in batch scenarios. Here’s a PowerShell one-liner to extract text from all PDFs in a folder:
| Tool | Time to extract all text | Memory usage | |------|------------------------|--------------| | xpdf pdftotext | 0.47 seconds | 8 MB | | Python PyPDF2 | 1.8 seconds | 45 MB | | Adobe Acrobat (Save As Text) | 6.2 seconds | 210 MB | | Microsoft Edge “Save as Text” | 2.1 seconds | 190 MB |
Look for → “Windows” → “64-bit” (or 32-bit if needed). The filename is typically xpdf-tools-win-4.04.zip . One Last Tip Don’t confuse xpdf-tools with the older Xpdf viewer (which had a GUI). The tools are a separate download. And if you’re on Linux, you can install via apt install xpdf-utils or similar – but on Windows, this ZIP is your best bet.
The 4.04 release is stable, well-tested, and free (under the GPLv2). It doesn’t phone home, doesn’t display ads, and doesn’t mysteriously expire. It just works – even on Windows 11, Windows Server 2022, and Windows 10 LTSC.
Browse the latest blog posts for in-depth insights into anti-detection and online privacy. Stay up-to-date!



Submit your need here, we will check and give you reply asap.



